ICMP, Ping, and Traceroute - What I Wish I Was Taught
Posted on May 10, 2020
- and tagged as
- networking
I wanted to write a post and do a bit of a deepdive into ICMP, ping and traceroute. I’ve found that having a good networking foundation has been a tremendous help in my day to day work. So if you’ve ever used ping or traceroute, and wanted to know a little more, read on.
I’m not going to cover every detail, but a few key topics that have helped me troubleshoot and better understand issues over the years.
ICMP and Ping
ICMP (Internet Control Message Protocol)
Most traffic on the internet is encapsulated in either TCP, or UDP. Ping however uses a protocol called ICMP. ICMP is a diagnostic protocol and has a number of different message types, each one responsible for communicating a specific event - be it a ping request (called an Echo Request), a ping reply (called an Echo Reply), or a number of other diagnostic results.
Each message type consists of two fields, a Type field, which is a general grouping of similar sub-types, called Codes. For example, the Destination Unreachable type contains multiple Codes, one of which is 1, which maps to the message Destination host unreachable. A complete list of ICMP Types can be found on Wikipedia.
You’ve no doubt seen these messages when doing pings. If I ping an IP on a network I know my router doesn’t have a route for, we get a Destination host unreachable message from the router (Reply from 10.250.1.1).
C:\>ping 10.44.44.4
Pinging 10.44.44.4 with 32 bytes of data:
Reply from 10.250.1.1: Destination host unreachable.
Reply from 10.250.1.1: Destination host unreachable.
Reply from 10.250.1.1: Destination host unreachable.
Reply from 10.250.1.1: Destination host unreachable.
Ping statistics for 10.44.44.4:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss)If we check the ICMP Control Messages table, we can see Destination host unreachable maps to Type: 3, Code: 1. We can confirm this with a Wireshark capture, looking at the response packet.
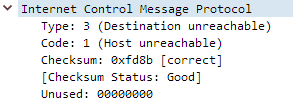
What’s happening here is our PC is sending a Type 8, Code 0 message which is an Echo Request to 10.44.44.4. This message reaches our default gateway which checks its routing table for that network, doesn’t find one, and responds to our request accordingly with a Destination host unreachable message.
There is one caveat worth mentioning if you’re trying this at home - this primarily applies to enterprise or business networks. Most residential routers will simply send all traffic they don’t have a specific route for out to the Internet, even if the destination IP is within the RFC1918 private address space. In this case the ISP will simply drop these packets and you will see a Request timed out message instead.
Request timed out does not map to an ICMP message type as it’s not a message, rather, it is the absence of any return data.
So why is all this important?
Know what ICMP messages mean
The returned ICMP message can give us clues as to what is actually happening. Destination host unreachable is very different from Request timed out.
Destination host unreachable tells us we don’t have an ARP entry for the target host. Destination net unreachable tells us we don’t have a path to the network. Request timed out tells us we have an ARP entry, and a route, but did not get a response.
Further, the system that replies with a Destination net unreachable is the system which doesn’t have a path to the requested network - so you immediately know where to start looking.
Let’s dig a little deeper into this because it gets interesting.
Pinging on your local network
What happens if you ping a non-existent host on your network? Do you get Request timed out, Destination host unreachable, or something else? What happens if the device is live, but the firewall is blocking ICMP? Can you tell the difference between a non-existent host, and one that simply discards ICMP Echo Requests?
With these questions in mind, let’s ping a device that is set to discard ICMP Echo Requests and see what happens.
C:\>ping 10.250.1.5
Pinging 10.250.1.5 with 32 bytes of data:
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Ping statistics for 10.250.1.5:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss)Let’s examine how that looks in Wireshark.

We sent 4 ICMP Echo Requests and got no replies, resulting a Request timed out, which is what we would expect when a device’s firewall is set to drop ICMP.
However, what if the device was not on the network at all? Would we get the same result? For this example I’ve removed the device from the network.
C:\>ping 10.250.1.5
Pinging 10.250.1.5 with 32 bytes of data:
Reply from 10.250.1.100: Destination host unreachable.
Reply from 10.250.1.100: Destination host unreachable.
Reply from 10.250.1.100: Destination host unreachable.
Reply from 10.250.1.100: Destination host unreachable.
Ping statistics for 10.250.1.5:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss)And let’s look at Wireshark.

Your eyes aren’t deceiving you, there is nothing there - we’re not even sending a single Echo Request.
What is happening here has to do with how packets are switched inside a network segment. When you ping a remote resource (something on the Internet, or on another VLAN), the Layer 2 destination address on the packet is set to your default gateway’s MAC address. However, when you send traffic to a device on your local network, the router does not need to get involved, so the Layer 2 destination address is set to the MAC address of the destination device.
And how does our computer know what the MAC address is? It broadcasts out an ARP Request and listens for the reply containing the address. As there is no device on the network to respond to the ARP Request, the ICMP Echo frame cannot be created, and therefore it never gets sent.
If I change the Wireshark filter to show ARP traffic, here’s what we see.

We’re broadcasting out ARP Requests, but as there is no device to respond nothing is returned. Let’s take a look at the full capture (Both ARP and ICMP) of the previous example where the host was live, but dropping ICMP.

There it is, we make the same initial ARP Request, but this time we receive a reply with the MAC address, which lets our computer create an appropriately addressed Layer 2 frame, and enables the Echo Requests to be sent.
This essentially means we don’t really need ICMP to detect hosts on our local subnet, if we have an entry in our ARP cache for the IP we’re looking for, it most likely means there is something there.
C:\>arp -a 10.250.1.5
Interface: 10.250.1.100 --- 0xa
Internet Address Physical Address Type
10.250.1.5 6c-41-6a-54-3d-0e dynamicDespite not receiving a reply to our ping, we can tell there is something there purely by the presence of an entry in our ARP table, or to put it another way, by the fact that we’re even sending ICMP Echo Requests.
To summarize, Destination host unreachable on the same subnet means that there is nothing there, Request timed out means there could be something there, but it’s blocking ICMP.
These are safe rules of thumb, but there are always exceptions.
Your PC may have a cached ARP entry that’s being used to generate the packets. You can clear your ARP cache on Windows with arp -d in an administrative command prompt.
Windows has some interesting rules around how it maintains and flushes the local ARP cache.
Here we can see the effect of those rules, I’ve re-enabled the device with the address of 10.250.1.5, and have removed the firewall rule that blocks ICMP. After a few successful pings I’ve once again removed the device from the network.
C:\>ping -t 10.250.1.5
Pinging 10.250.1.5 with 32 bytes of data:
Reply from 10.250.1.5: bytes=32 time<1ms TTL=255
Reply from 10.250.1.5: bytes=32 time<1ms TTL=255
Reply from 10.250.1.5: bytes=32 time<1ms TTL=255
Reply from 10.250.1.5: bytes=32 time<1ms TTL=255
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Request timed out.
Reply from 10.250.1.100: Destination host unreachable.
Reply from 10.250.1.100: Destination host unreachable.
Reply from 10.250.1.100: Destination host unreachable.
Reply from 10.250.1.100: Destination host unreachable.
Reply from 10.250.1.100: Destination host unreachable.We can see the first few replies, followed by the device being unplugged, the MAC address remaining in our cache resulting in Request timed out due to lack of replies to our pings, eventually Windows purges the cached entry, and our ARP requests once again go unanswered, finally resulting in Destination host unreachable as we can no longer send the ping requests.
Lastly, another ‘feature’ that can mess with ARP is Proxy ARP, though this is rarely enabled (and if it is, it’s more than likely due to misconfiguration or the use of Private VLANs)
Let’s move onto another useful ICMP message code.
Detecting closed ports
Sometimes (definitely not always), when a firewall is configured to deny a connection an ICMP message is returned to indicate that the connection is Administratively Prohibited. This has saved me a lot of going back and forth between teams blaming firewalls, servers, etc. A very simple way to test a TCP service is by doing a telnet to the port you want to reach.
In this example I’ll try a telnet to port 80 on my router, which I know is explicitly blocked.
C:\>telnet 10.250.1.1 80
Connecting To 10.250.1.1...Could not open connection to the host, on port 80: Connect failedOk, so telnet itself doesn’t give us the actual ICMP code, but what about Wireshark?

Bingo, we can see a reply from the router with Communication administratively filtered. This tells us our packet is making to all the way to the device (so it’s not being blocked by another firewall or some other network control software like AV heuristics or an IPS), and that the device itself is telling us that the port is not open for business.
We can again confirm the ICMP message type and code in the Wireshark capture.
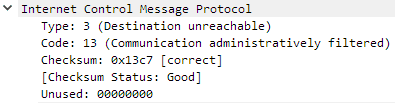
The great thing about this method, is we can tell exactly which device is blocking the connection. I’ve adjusted the firewall rule on my router to block all traffic to port 80 to any host. Let’s see what happens when I try to telnet to google.com on port 80.

We can see my PC (10.250.1.100) sending the initial TCP SYN packet to the IP which google.com resolved to (216.58.203.110), however, the ICMP reply has originated from the local firewall - 10.250.1.1, telling us that connection to that resource has been denied. This process is repeated several times as my PC stubbornly retries several more times with the same result.
While this is a very simple example, in larger corporate networks it can be useful to quickly identify which system is blocking a connection as those networks tend to have much more complexity and it’s not always obvious.
A quick side note here, while somewhat off topic it’s worth mentioning. Many firewalls will instead send back a spoofed TCP RST packet instead of an ICMP Communication administratively filtered message. This especially applies to web filtering or IPS systems which are not inline, but are connected to a SPAN/mirror port.
Security and Path MTU Discovery
We can see in the previously linked Wikipedia page that there are many ICMP Types and Codes. Some have been deprecated, and many are generally not used.
Your firewall rules should be configured to permit specific ICMP Types and Codes - do not blindly permit all ICMP because you want pings to work, and don’t blindly drop all ICMP because there are some message types that could be abused. There is a good post on Security StackExchange which discusses some ICMP types that are commonly permitted, and some you should always block.
That’s it for ICMP Types, lets move on.
High latency isn’t always a problem
Many times when we use ping we’re not only looking at reachability, but also latency. While high latencies can often be problematic, it’s not always the case. Lets examine a scenario where a high ping to a device may not be a problem.
Most modern enterprise routers and switches perform packet forwarding (routing and switching) in ASICs (Application Specific Integrated Circuits). These are hardware chips inside the device that are dedicated to these functions, and they are fast. The vast majority of packets passing through a router or switch are handled by ASICs.
However, a packet that is destined for the device, is not. They are punted off to the general purpose CPU which handles many other tasks, such as routing updates, packet fragmentation, etc. This creates the possibility of a scenario where a router may be CPU starved, but still be able to process normal packet forwarding at the usual hardware accelerated speeds.
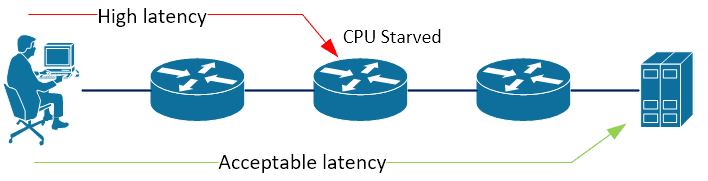
This manifests itself as high latency to a specific hop (device) along the path to the desired resource, but acceptable latency to the end resource.
Even if the device is not CPU starved, there are control plane policies that network administrators can define which effectively apply QoS rules that can have a detrimental effect on ping response times. These policies are designed to ensure that critical services such as routing updates and management access are not interrupted by excessive non-critical traffic such as ICMP packet processing. In some cases ICMP packets are completely dropped if the configured policy threshold is hit - this can look like packet loss, but many times isn’t relevant to normal packets simply passing through the device as they do not have these policies applied to them.
Don’t make the assumption that if a device along the path is slow to respond to a ping (or only responds intermittently) that the issue lies on that device.
Round trip times and Asymmetric Routing
Finally, what are we actually measuring when we look at ping latency? It’s measurement of round trip time, that is, the ping request being sent from your PC, reaching the destination device, being processed, a reply being generated, sent back to your PC, and processed.
The Internet is complex, with peering agreements between ISPs and entities largely determining which path a packet takes through the web. A key concept is that the path to a device may not be the same as the return path from that device.
Consider the following simplified diagram, the sever is located in a datacenter with two internet connections via different ISPs.

Due to peering arrangements, the datacenter provider prefers the path in green when sending data to your ISP, but they don’t have a lot of control over how data is sent to them from your ISP. The result is that the ICMP Echo Request takes the path in blue, while the ICMP Echo Reply takes the path in green.
What if there is congestion or a fault on the link drawn in red? You’re going to see high latency when you ping the server, but it won’t have anything to do with the server or datacenter.
That’s it for pings, but lets continue the asymmetric routing story with traceroute.
Traceroute
Refresher - How does traceroute work?
It’s important we’re all on the same page regarding the operation of traceroute, so let’s quickly cover it.
Traceroute works by sending packets to the final destination, starting with an IP TTL (Time To Live) of 1, and incrementing it after every hop until a reply is received from destination resource. TTL is a field in the IP header that is decremented by 1 at each layer 3 device it passes through. When it reaches 0 the packet stops being forwarded, an error is generated and returned within an ICMP packet.
This means, since traceroute starts with a TTL of 1, every hop along the way to our destination receives a packet where the TTL is decremented to 0, and therefore responds with an ICMP Time to live exceeded in transit message, which is ICMP Type 11, Code 0.
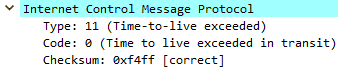
This ordered flow of ICMP TTL Exceeded packets is what allows us to map the path to the resource. Here is an example traceroute from my PC to 1.1.1.1
C:\>tracert 1.1.1.1
Tracing route to one.one.one.one [1.1.1.1]
over a maximum of 30 hops:
1 <1 ms <1 ms <1 ms 10.250.1.1
2 * * * Request timed out.
3 16 ms 16 ms 16 ms 58.160.251.129
4 20 ms 12 ms 17 ms bundle-ether4.way-edge901.adelaide.telstra.net [203.50.116.104]
5 19 ms 35 ms 14 ms bundle-ether9.way-core10.adelaide.telstra.net [203.50.11.156]
6 16 ms 26 ms 14 ms bundle-ether1.way-edge903.adelaide.telstra.net [203.50.6.13]
7 24 ms 13 ms 24 ms twi3395298.lnk.telstra.net [203.54.226.194]
8 11 ms 12 ms 13 ms one.one.one.one [1.1.1.1]
Trace complete.Let’s see how lines 1 and 2 look in Wireshark.

There are a few things to note.
- Firstly, the destination for packets sent by my PC (
10.250.1.1) is always1.1.1.1. - We send 3 ICMP Echo Requests to each hop before the TTL is incremented, these map to the latency figures seen in the output
- The packets begin with a TTL of 1 for the first hop, and are incremented to 2 for the second hop
- The second hop does not respond, therefore we show a
Request timed outand move on - By default, Windows uses ICMP packets for traceroute, while Linux uses UDP (not relevant here but it’s useful interview trivia)
Let’s pick up where we left off - asymmetric routing.
Asymmetric Routing - Traceroute edition
One of the most important concepts to understand when looking at traceroute data to is that you’re only seeing one path - the path from the source device (where the traceroute command is ran) to the destination device. As our diagram above shows, return packets may take a completely different path, but we have absolutely no visibility into this.
Let’s demonstrate this with a quick lab. I have the following configured in GNS3.
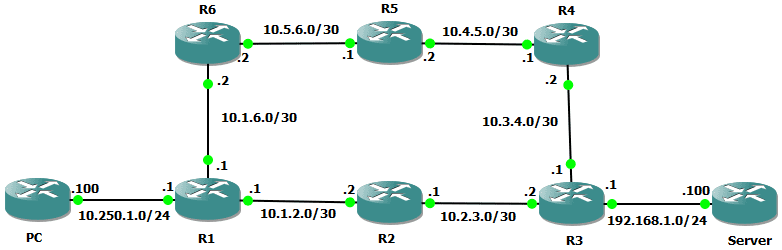
The configuration is fairly simple, we’re using two routers to emulate a PC and a Server (labelled as such). Packets from the PC to the Server take the lower path via PC -> R1 -> R2 -> R3 -> Server, but packets from the Server to the PC take the upper path via Server -> R3 -> R4 -> R5 -> R6 -> R1 -> PC.
Let’s see what this looks like in a traceroute, first from the PC to the Server. The output will be a little different to before as we’re doing this in Cisco IOS CLI but it should still make sense. We can also ignore the reported latencies as they are of no relevance here and are caused by emulated hardware.
PC#traceroute 192.168.1.100
Type escape sequence to abort.
Tracing the route to 192.168.1.100
1 10.250.1.1 28 msec 16 msec 24 msec
2 10.1.2.2 40 msec 36 msec 36 msec
3 10.2.3.2 80 msec 76 msec 88 msec
4 192.168.1.100 84 msec 124 msec 108 msecWe can see the exact path we described above. How about from the Server to the PC?
Server#traceroute 10.250.1.100
Type escape sequence to abort.
Tracing the route to 10.250.1.100
1 192.168.1.1 16 msec 20 msec 16 msec
2 10.3.4.2 40 msec 44 msec 36 msec
3 10.4.5.2 76 msec 44 msec 76 msec
4 10.5.6.2 60 msec 104 msec 92 msec
5 10.1.6.1 80 msec 76 msec 60 msec
6 10.250.1.100 112 msec 120 msec 84 msecThere we have it - a completely different path to before. If we only had a traceroute from one side of the connection we would have zero insight into what the return path looked like. What if the issue we were diagnosing was along the return path? A single traceroute would be of little use, and could cause us to misdiagnose the issue. Let’s simulate that - I’m going to bring down the link between R5 and R6. What will the traceroute from the PC to the Server look like? Place your bets!
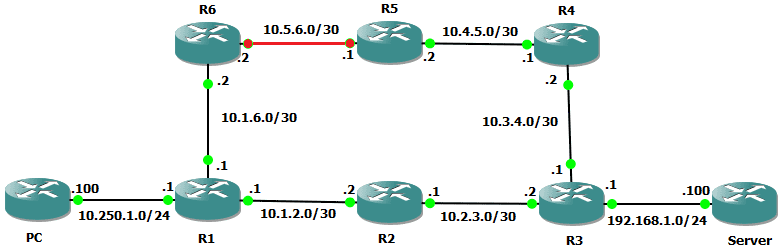
PC#traceroute 192.168.1.100
Type escape sequence to abort.
Tracing the route to 192.168.1.100
1 10.250.1.1 24 msec 24 msec 16 msec
2 10.1.2.2 36 msec 36 msec 48 msec
3 * * *
4 * * *
5 * * *
6 * * *
7 * * *
# Output truncated...
Despite the fault being on R5, our output shows no indication of that, in fact, many would look at this and conclude that the issue is on R2 since our packets get no further. What is actually happening is that every device after R2 (so from R3 onwards) the return packets take the upper path which is not able to route the traffic due to the broken link.
However, if we now attempt the traceroute from the server, we get a more accurate picture.
Server#traceroute 10.250.1.100
Type escape sequence to abort.
Tracing the route to 10.250.1.100
1 192.168.1.1 16 msec 16 msec 20 msec
2 10.3.4.2 32 msec 40 msec 44 msec
3 10.4.5.2 64 msec 44 msec 76 msec
4 10.4.5.2 !H !H !HThe !H in the output from 10.4.5.2 maps to Host Unreachable in Cisco IOS syntax - that is, R5 no longer has a path (route) to our final destination of 10.250.1.100.
For this reason when using traceroute to troubleshoot connectivity issues it’s really important to try to get the results from both sides of the connection.
Let’s move on to an interesting side effect MPLS networks have on reported traceroute latencies.
Traceroute and MPLS
With normal IP routing each device along a path decides how to route the packet. The destination IP address is pulled out of the IP header, a routing table lookup is done, and the packet is sent on its way, out whatever interface that particular router decided was the best for that destination network.
With MPLS (Multiprotocol Label Switching) the first router in the path determines the entire path to the destination, and all subsequent routers mindlessly adhere to that path.
The caveat here is that even diagnostic error packets, such as those generated when a TTL Expired condition occurs are still sent on along the entire path before being returned to the source.

Imagine any router in the path being being in a different country or state, this has the inadvertent effect of showing a consistently high latency across the entire traceroute (or at least across the MPLS sections of the path) as each TTL Expired message must traverse the full path before being sent back.
That’s it for now, hope this has been useful, ping me if you have any comments!